
Data Scientists are unique professionals skilled in interpreting complex datasets and using their understanding of mathematics, statistics, and computer science to generate insights. In tech interviews, questions for data scientists often focus on understanding of machine learning algorithms, statistical modeling, data cleaning and data visualization techniques. These interviews test an individual’s capacity to extract relevant information from data and provide strategic recommendations to solve complex problems or drive decisions within a business context.
Content updated: April 19, 2024
Fundamentals of Machine Learning for Data Scientists
- 1.
What is Machine Learning and how does it differ from traditional programming?
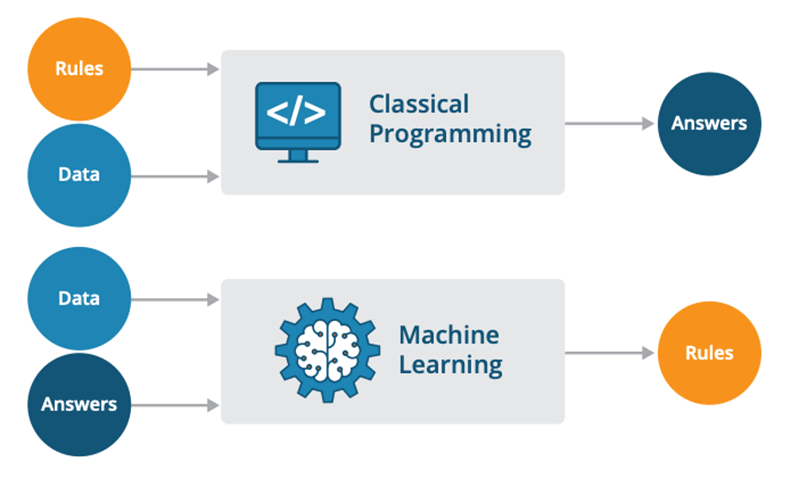
Answer:Machine Learning (ML) and traditional programming represent two fundamentally distinct approaches to solving tasks and making decisions.
Core Distinctions
Decision-Making Process
- Traditional Programming: A human programmer explicitly defines the decision-making rules using if-then-else statements, logical rules, or algorithms.
- Machine Learning: The decision rules are inferred from data using learning algorithms.
Data Dependencies
- Traditional Programming: Inputs are processed according to predefined rules and logic, without the ability to adapt based on new data, unless these rules are updated explicitly.
- Machine Learning: Algorithms are designed to learn from and make predictions or decisions about new, unseen data.
Use Case Flexibility
- Traditional Programming: Suited for tasks with clearly defined rules and logic.
- Machine Learning: Well-adapted for tasks involving pattern recognition, outlier detection, and complex, unstructured data.
Visual Representation
Code Example: Traditional Programming
Here is the Python code:
def is_prime(num): if num < 2: return False for i in range(2, num): if num % i == 0: return False return True print(is_prime(13)) # Output: True print(is_prime(14)) # Output: FalseCode Example: Machine Learning
Here is the Python code:
from sklearn.model_selection import train_test_split from sklearn.ensemble import RandomForestClassifier from sklearn.datasets import load_iris import numpy as np # Load a well-known dataset, Iris data = load_iris() X, y = data.data, data.target # Assuming 14 is the sepal length in cm for an Iris flower new_observation = np.array([[14, 2, 5, 2.3]]) # Using Random Forest for classification model = RandomForestClassifier() model.fit(X, y) print(model.predict(new_observation)) # Predicted class - 2.
Explain the difference between Supervised Learning and Unsupervised Learning.
Answer: - 3.
What is the difference between Classification and Regression problems?
Answer: - 4.
Describe the concept of Overfitting and Underfitting in ML models.
Answer: - 5.
What is the Bias-Variance Tradeoff in ML?
Answer: - 6.
Explain the concept of Cross-Validation and its importance in ML.
Answer: - 7.
What is Regularization and how does it help prevent overfitting?
Answer: - 8.
Describe the difference between Parametric and Non-Parametric models.
Answer: - 9.
What is the curse of dimensionality and how does it impact ML models?
Answer: - 10.
Explain the concept of Feature Engineering and its significance in ML.
Answer:
Data Preprocessing and Feature Selection
- 11.
What is Data Preprocessing and why is it important in ML?
Answer: - 12.
Explain the difference between Feature Scaling and Normalization.
Answer: - 13.
What is the purpose of One-Hot Encoding and when is it used?
Answer: - 14.
Describe the concept of Handling Missing Values in datasets.
Answer: - 15.
What is Feature Selection and its techniques?
Answer: